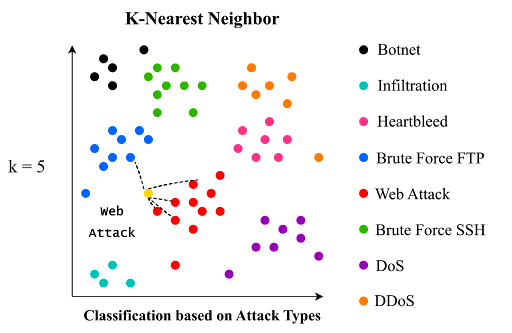
As a supervised learning clustering model, K-Nearest Neighbor calculates the distances, usually Euclidean distances, between new and classified data to find the correlations. As a classification method, this model is capable of allocating data to multiple categories, which expands the number of classification tasks it can complete. The figure below is a brief simulation of how the model works to classify new data to a specific attack type.
As the figure above shows, there are eight cyber attack types, including brute force FTP, brute force SSH, DoS, heartbleed, web, infiltration, botnet, and DDoS attacks, each with its distinct patterns which the model recognizes. The yellow dot in the figure is a new piece of data that is not yet classified into any type of attack. Classification, however, requires a value of k to be set. The k-value represents how many closest neighbors, in this case, classified data, the new data has. In this case, it is set to 5. Out of the 5 closest neighbors to the yellow dot, there is 1 blue dot and 4 red dots, which means that the new data, yellow dot, should be a web attack, since the majority of its five nearest neighbors are red. Using this example, K-Nearest Neighbor’s benefits as a machine learning classifier are evident, illustrating its use as an algorithm for any classification or regression tasks.




